Like ℵ0 File Systems for Everyone¶
If the ideal blog post is but a screenful or two, this one fails rather badly. So badly, in fact, that I’ve decided to split it into three, each of which will itself be amply proportioned. This post discusses the analogy between the Unix File System and Fluidinfo, as a way of preparing the ground for the following posts. The second post will build on that to discuss options for syntax of potential cp and mv commands in Fish. The final post in the series will discuss upload and download, or maybe rcp, rsync and ftp; as well as possibly fsync, i.e., commands for copying parts of a local file system to or from Fluidinfo.
Everyone loves the Unix File System, even through the expletives we utter at those moments when our ardour is temporarily diminished.
The Fluidinfo Shell, Fish, is largely built on the idea of mapping Fluidinfo namespaces to Unix directories, tags to files, and tag values to the contents of files. Fish’s commands are mostly constructed with close and deliberate reference to corresponding Unix commands.
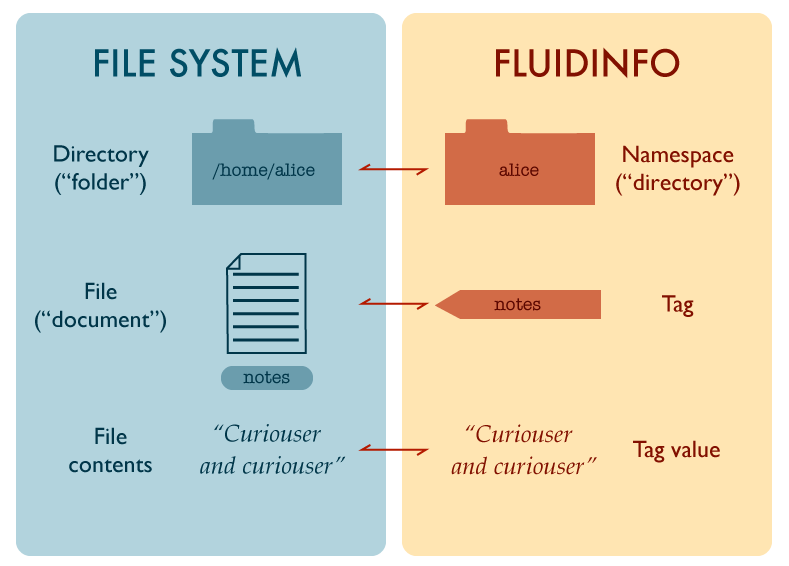
Fluidinfo and Unix diverge in several small and one large way when viewed through the lens of this analogy.
- In Unix, a path (such as /Users/njr/foo) resolves either to a file or to a directory, but not both; in Fluidinfo, a file and a namespace may share a path. This difference causes a number of complications in mapping Unix commands to Fluidinfo.
- In Unix, full paths begin with a slash (/) and the Unix kernel works only with such full paths. The shell maintains a notion of a current working directory and allows the user to refer to files relative to that. The Fluidinfo Shell, Fish, does something similar in the context of Fluidinfo, but effectively clamps the working directory to the user’s home namespace (njr, in my case).
- To a first approximation, Unix provides only a single hierarchical file structure for each user: Fluidinfo provides an infinite number of them—one for every possible about tag text and one for each UUID. (There are 2128, or some 340 decillion = 3.4 ⨉ 1038, UUIDs). It is this infinite number of potential about tags motivates the title of this piece: ℵ0 (“aleph zero”) is the smallest infinity—the number of counting numbers. Non-mathematicians may be unaware, and skeptical, of the idea that there can be infinities of different sizes, but thanks the remarkable work of Georg Cantor, we can be quite confident that this is so. Infinite sets require some care, and have surprising properties: for example, ℵ0 is not only the number of positive whole numbers, but also the number of whole numbers (positive and negative). Even the number of rational numbers (fractions) is the same. It is only when we add in the irrationals, to form the real numbers, which are vastly more numerous than the rationals, that we get a larger cardinal, ℵ1. Needless to say, while Fluidinfo does in principle offer ℵ0 tag hierarchies to each user, just as real-world Turing machines are limited by the inability of Maxell to supply an infinite tape, the maximum possible size of Fluidinfo itself is limited by the physical properties of the universe, not to mention the finite capacity of even Amazon’s Simple Storage System, S3.
It is this last difference—a tag hierarchy for each Fluidinfo object—that is most significant. One way of thinking about it is this: on Unix (at least considering a single host, with a single file system, in isolation) there is a single directory hierarchy containing everything, as illustrated on the left in the diagram below.
In contrast, we can think of Fluidinfo as having a tag hierarchy, with (potentiall) different tag values for the same tag, on each of a very large number of objects.
Some tags in the tag heirarchy are present on many objects, others on only one, or even none (since there is a notion of an abstract tag in Fluidinfo, separate from any concrete instances of it actually attached to objects).
The tag heirarchies on all the objects can be viewed as a single structure, only part of which is present on any object. I’ve attempted to show this with dark tags and directories for instantiated parts of the Fluidinfo hierarchy on each objects, with parts instantiated elsewhere left pale in the diagram below. I’ve illustrated two whiskies (which use the same parts of the overall hierarchy) and one city, which uses mostly different tags.
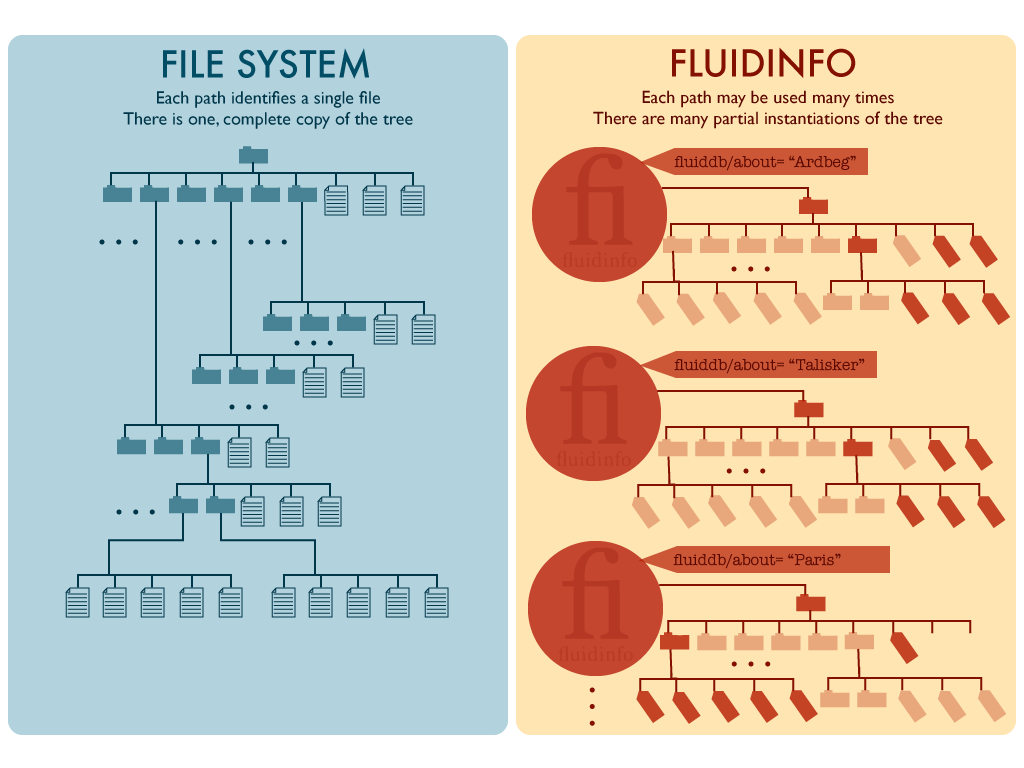
We might call this way of thinking about the Fluidinfo tag structure as the the many tag hierarchies view. Sometimes this seems like the natural way to think about Fluidinfo’s tag hierarchy, with the tag structure being in some sense inferior to the objects. The objects might then be likened to different hosts in a computer network, and tags could be thought of as having a single value in each separate hierarchy, just as the contents of a single file is well-defined and unambiguous on a specific computer.
At other times, it seems more natural to think of the tag hierarchy as the primary entity with the with tags having different values on different objects. I’ve tried to illustrate this below, with different collections of objects hanging off tags in a single hierarchy.
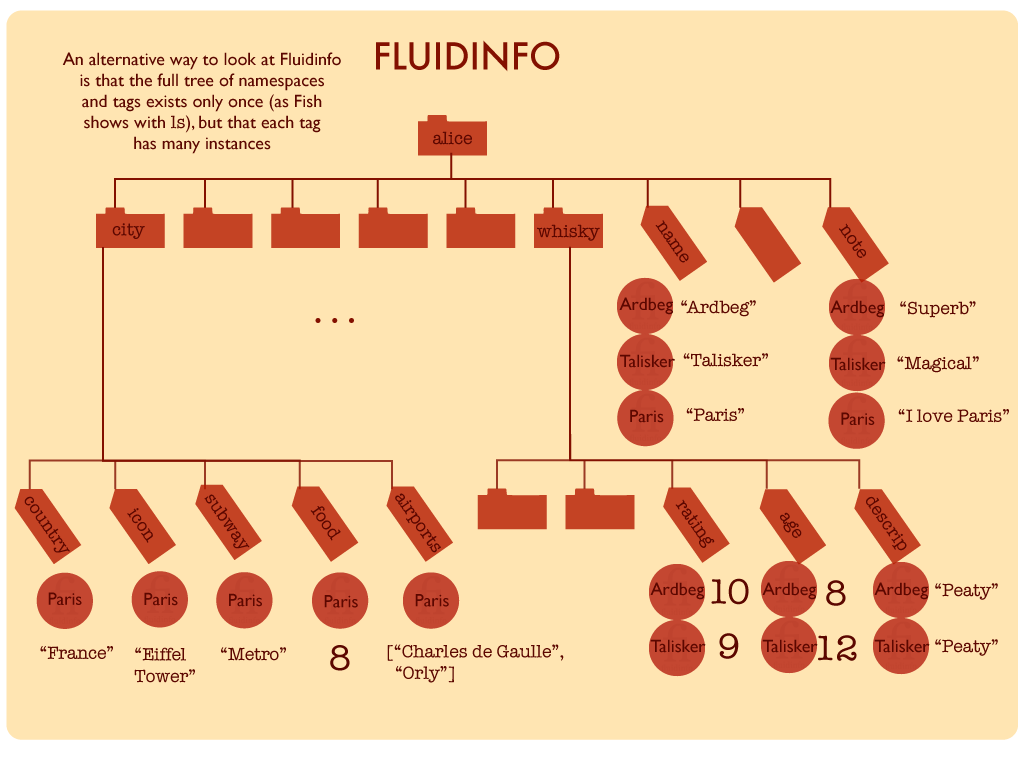
We might call this the single tag hierarchy view.
Neither of these views is really more correct that the other—the underlying storage mechanism looks little like either, though is perhaps slightly closer to the second view, in the sense that all the values for a given tag are stored together in the database.
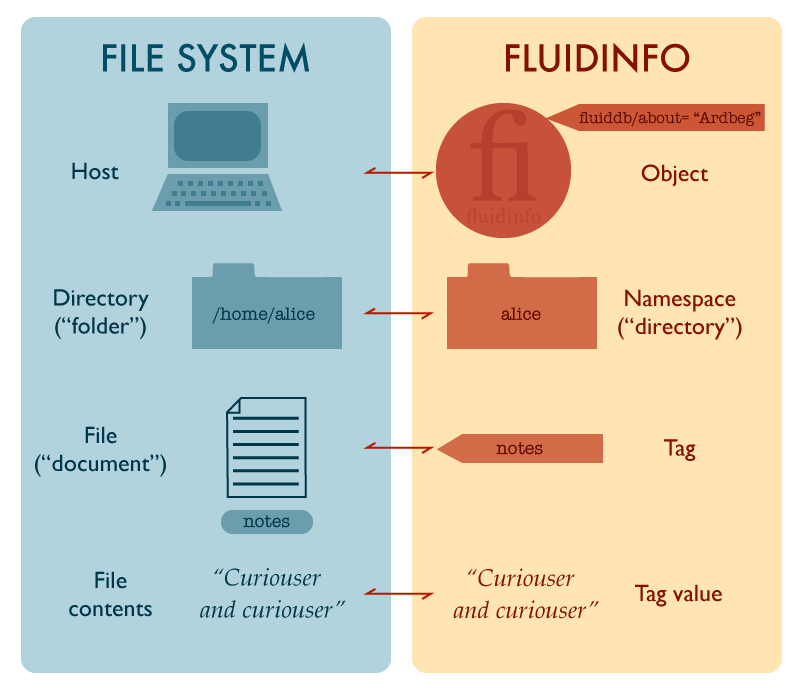
Fluidinfo’s addressing mechanism, however, is very like the “many tag hierarchies” view. After all, the address to access Alice’s whisky/age tag on Ardbeg is
http://fluiddb.fluidinfo.com/about/Ardbeg/alice/whisky/rating
Ignoring the base URL (http://fluiddb.fluidinfo.com) we then have something remarkably familiar from Unix, and comparable either to a host or a volume (/about/Ardbeg), followed (after a separating slash) by the tag path (/alice/whisky/rating). Notice how similar this is, for example, to the way we address files across systems using Unix’s remote copy command, rcp. If Alice wanted to copy a file from the host ardbeg on her local area network, she might say
rcp ardbeg:whisky/rating ./whisky/ardbeg-rating
or:
rcp ardbeg:/Users/alice/whisky/rating whisky/ardbeg-rating
or even, if she were on host talisker, and wished to be more explicit
rcp ardbeg:/Users/alice/whisky/rating talisker:/Users/talisker/whisky/ardbeg-rating
Similarly, if she has multiple file systems mounted on her machine, Alice might say something like:
cp /Volumes/whiskydata/whisky/ardbeg/rating /Users/alice/whisky/ardbeg-rating
where now /Volumes/whiskydata is a disk (or file system).
We could also note that an alternative way of specifying the previous rcp command would be:
rcp /Users/alice/whisky/rating@ardbeg ./whisky/ardbeg-rating
This is entirely equivalent, but looks slightly more like the “single tag hierarchy” view, at least in the sense that the disambiguating host comes after—rather than before—the tag path.
However we lay things out, it feels fairly clear that there is a good case for extending our analogy to include either volumes, or more likely hosts as the file-system analogues of Fluidinfo’s objects.
That concludes the introduction to this series. In the next part, I’ll discuss how these alternative views might help us to decide the best way to implement mv and cp commands in Fish.