A Search Engine for Fluidinfo¶
I wrote an extremely simple search front-end for Fluidinfo which you can access at http://abouttag.appspot.com/search.
It is extremely simple. You type one or more search terms into the box and it “searches” Fluidinfo about tags for those terms.
For example, here’s what happens if you type in solitude:

and here’s what happens if you type in marquez book:
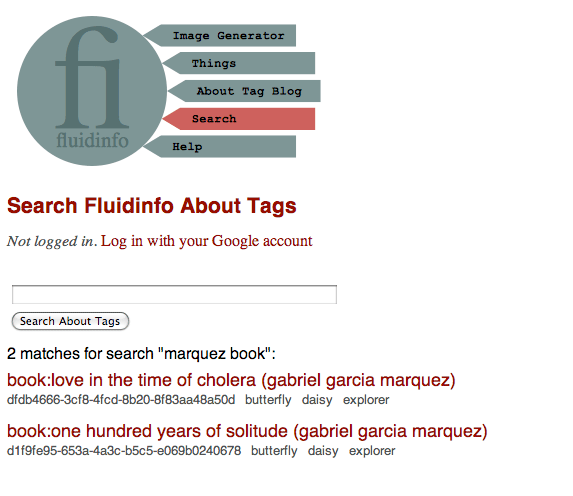
Here’s what you need to know:
All this does is turn this into a values query on Fluidinfo that ANDs together the search terms (after white-space stripping). So the query part for these two searches become
fluiddb/about matches "solitude"and
fluiddb/about matches "marquez" AND fluiddb/about matches "book"respectively.
I don’t fully understand Fluidinfo’s string matching, which is based on Lucene, but it is fairly search-engine like. I think the following is true:
- case is ignored in matching
- punctuation is discarded
- only whole-words match
- accented characters match themselves (case insensitively) and not their non-accented counterparts, and vice versa. So café matches CAFÉ but not cafe and CAFE matches cafe but not CAFÉ. (This was broken when this was originally posted, but is fixed now.)
If we’re lucky, Manuel (@ceronman) or Esteve (@esteve) might add clarification in the comments, which I will promote to here if appropriate.
Consequences of the above include:
- You can’t search on prefixes like film:, because the puntuation is discarded (though you can search on film and it will match things containing film:)
- There is no stemming or substring matching, so soli won’t match solitude etc.
At the moment a maximum of 100 results are returned and there is no paging implemented; I plan to add that soon.
Result order is essentially random. If I implement paging, I will probably sort them. My first thought is to sort them as shortest-to-longest, with an alphabetical subsort to break ties. (Comments?)
Various links are returned for each matching object.
- The main link points to the raw Fluidinfo object, accessed though /about. This will show you its tags as a JSON dump.
- The object’s ID is shown underneath, and that links to the raw object in Fluidinfo, this time through /objects.
- Links to both the butterfly and daisy visualizations from http://abouttag.com are provided.
- Finally, a link to the object in P A Parent’s Fluidinfo Explorer is given.
I thought about adding a curl link too, that would show the syntax for accessing the object with curl (cURL, if you prefer), but I couldn’t really think of a neat way of doing it; a link to a one-line page seems over the top and I hate pop-ups. I suppose some kind of javascript manipulation to show the curl text below would be a possibility. Let me know if you would find this useful.
Like the rest of the About Tag site, the application is built on Google’s App Engine. Unfortunately, this implements a time-out after 10 seconds on all HTTP requests, and even more unfortunately, some searches in Fluidinfo take more than 10 seconds. If you see a time-out, that’s probably what’s happening. This is usually because too many results are being returned. Unfortunately, Fluidinfo does not implement any form of paging or limiting of results at the moment, so the only way round this is to write a more specific query that will have fewer results.
For example, at the moment, when I search on book, it consistently times out; if I instead search on book orwell, it consistently works.
There’s not much I can do about this: the Fluidinfo team is working hard on making Fluidinfo faster and is (I believe) actively considering implementing some kind of paging mechanism.
At the moment, only the about tag (fluiddb/about) is searched, (which is, I suppose, appropriate for this blog/site). It would be very easy for me to provide other interfaces. One obvious thing would be to allow the user to select the tag searched, and another would be to allow a full Fluidinfo query to be typed. If there’s interest, I can do these.
If you want to jump straight to results, you can just add a ?q=terms to the end of the search URL (http://abouttag.appspot.com/search). For example, http://abouttag.appspot.com/search?q=george+orwell will reveal what Fluidinfo knows about the great man. Use + to separate search terms in the URL or, if you prefer, use percent encoding.
This was implemented extremely quickly, and has only been tested very briefly. Let me know if you find problems, whether you find it useful, if you’d like any of the other versions etc.